ଗୁଗୁଲ୍ର ଅକ୍ଷର ଚିହ୍ନିବା ସଫ୍ଟୱାର୍ ଏବେ ଦକ୍ଷିଣ ଏସିଆର ସବୁ ଭାଷା ପାଇଁ କାର୍ଯ୍ୟ କରୁଛି



ଅଧିକାଂଶ ଦକ୍ଷିଣ ଏସୀୟ ଭାଷାରେ କାର୍ଯ୍ୟ କରୁଥିବା ଗୁଗୁଲ୍ର ଅପ୍ଟିକାଲ୍ କ୍ୟାରେକ୍ଟର ରେକଗନେସନ ସଫ୍ଟୱାର୍ । ଫଟୋ: Subhashish Panigrahi, freely licensed under CC-by-SA 4.0.
ଗୁଗୁଲ ତିଆରିଅପ୍ଟିକାଲ୍ କ୍ୟାରେକ୍ଟର ରେକଗନେସନ (OCR) ସଫ୍ଟୱାର୍ ଦକ୍ଷିଣ ଏସିଆର ପ୍ରମୁଖ ଭାଷା ସହିତ ବିଶ୍ୱର ୨୪୮ଟିରୁ ଅଧିକ ଭାଷାରେ କାର୍ଯ୍ୟ କରୁଛି । ଏହା ଖୁବ ବ୍ୟବହାର ଉପପୋଗୀ ଏବଂ ପ୍ରାୟ ଭାଷା ପାଇଁ ୯୦ ଶତକଡ଼ାରୁ ଅଧିକ ସଠିକ ।
ଭାଷାଗୁଡ଼ିକର ଅନୁଧ୍ୟାନ ପାଇଁ OCR ସଫ୍ଟୱାର୍ଟି ଅତ୍ୟନ୍ତ ଲାଭଦାୟକ । ପ୍ରକୃତପକ୍ଷେ କୌଣସି ହାତଲେଖା ଓ ଛପା ଲେଖାର ଚିତ୍ରରୁ ଲେଖା ବାହାର କରିବାରେ ସାହାଯ୍ୟ କରୁଥିବାରୁ ପୁରୁଣା ଲେଖା, ପାଣ୍ଡୁଲିପି ଅନ୍ୟାନ୍ୟ ଲେଖ ପାଇଁ ଦ୍ୱାର ଉନ୍ମୁକ୍ତ କରିଛି ।
କେତନ ପ୍ରତାପ ଏନଡିଟିଭି ଗ୍ୟାଜେଟରେ ଲେଖିଥିଲେ:
Users can start using the OCR capabilities in Drive by uploading scanned document in PDF or image form after which they can right-click on the document in Drive to open with Google Docs. After choosing the option, a document with the original image alongside extracted text opens, which can be edited. Google notes that users will not be required to specify the language of the document as the OCR in Drive will automatically determine it. The OCR capability in Google Drive is also available in Drive for Android.
ବ୍ୟବହାରକାରୀଗଣ OCR ବ୍ୟବହାର କରିବା ପାଇଁ ସ୍କାନ୍ କରାଯାଇଥିବା PDF ଫାଇଲ କିମ୍ବା ଚିତ୍ରକୁ ଡ୍ରାଇଭ୍ରେ ଅପ୍ଲୋଡ଼୍ କରିବେ । ପରେ ଏହି ଫାଇଲ ଉପରେ ରାଇଟ୍ କ୍ଲିକ୍ କରି ଗୁଗୁଲ୍ ଡକ୍ସରେ ଖୋଲିପାରିବେ । ଏହା ବାଛି ଏକ ଫାଇଲରେ ମୂଳ ଚିତ୍ର ସହିତ ଉଦ୍ଧୃତ ଲେଖା ଖୋଲିଥାଏ । ଏହି ଲେଖାକୁ ପରେ ସମ୍ପାଦିତ କରାଯାଇପାରିବ । ଗୁଗୁଲ୍ର ମତ ଅନୁସାରେ ବ୍ୟବହାରକାରୀଗଣଙ୍କୁ ଫାଇଲର ଭାଷା ବତାଇବା ଦରକାର ନାହିଁ କାରଣ ଡ୍ରାଇଭ୍ର OCR ଆପେଆପେ ଭାଷାଟି ଠିକ କରିପାରିବ । ଗୁଗୁଲ୍ ଡ୍ରାଇଭ୍ର OCR ସୁବିଧା Android ପାଇଁ ମଧ୍ୟ ଡ୍ରାଇଭ୍ରେ ଉପଲବ୍ଧ ହେଉଛି ।
ଅନେକ ବ୍ୟବହାରକାରୀ ଟ୍ୱିଟର୍ରେ ଗୁଗୁଲ୍ର ଏହି ସୁବିଧାକୁ ସ୍ୱାଗତ କରି ଖୁସି ପାଳନ ମଧ୍ୟ କରିଥିଲେ:
Optical Character Recognition #OCR in Google Drive recongnizes many indic languages including #Kannada give it a try http://t.co/99UkCJQ6gb
— Omshivaprakash (@omshivaprakash) August 28, 2015
ଗୁଗୁଲ ଡ୍ରାଇଭରେ ଥିବା ଅପ୍ଟିକାଲ କ୍ୟାରେକ୍ଟର ରେକଗନେସନ କନ୍ନଡ଼ ସମେତ ଅନେକ ଭାରତୀୟ ଭାଷା ପାଇଁ କାମ କରୁଛି । ପରଖିନିଅନ୍ତୁ ।
— ଓମଶିବପ୍ରକାଶ
@shylobisnett if you have access to a scanner, you can do OCR through google drive. works a bit faster.
— Whet Moser (@whet) August 27, 2015
ସାମୁହିକ ଦଳ ପରିଚାଳନାର ସବୁଠୁ ଅସୁବିଧାଜନକ କାମଟି ହେଲା କାଗଜରେ ଇମେଲ ସଂଗ୍ରହ କରିବା ।
– ସାଇଲ ବିସନେଟ
ଆପଣଙ୍କ ପାଖେ ସ୍କାନଟିଏର ସୁବିଧା ରହିଥିଲେ ଗୁଗୁଲ ଡ୍ରାଇଭ ବ୍ୟବହାର କରି ଆପଣ OCR କରିପାରିବେ । ଏହା ଟିକେ ଦ୍ରୁତତର ।
— ହୁଏଟ ମୋସର
Wow. Searching Google Drive for a keyword also returns results for images containing that keyword in the image. Didn't realise it did OCR.
— Mark Osborne (@mosborne01) August 25, 2015
ବାଃ! ଗୁଗୁଲ ଡ୍ରାଇଭରେ କିୱାର୍ଡ଼ଟିଏ ଖୋଜିଲେ ବି ସେ କିୱାର୍ଡ଼ଥିବା ଛବି ଦିଶୁଛି । ଜାଣି ପାରୁନଥିଲି ଯେ ଏଇଟା OCR ହେଉଛି ବୋଲି ।
— ମାର୍କ ଓସବର୍ଣ୍ଣ
ସାଧାରଣରେ ପୁରଣା ଫାଇଲ କିମ୍ବା କାଳିର ଚିହ୍ନଥିବା ଓ ଦାଗ ଥିବା ପୃଷ୍ଠା ସ୍ପଷ୍ଟ ଭାବେ ଲେଖାଯିବା ପରିବର୍ତ୍ତେ ଖେଳିଯାଇଥିବା ଲେଖା ପରି ଥାଏ । ସେହି ଲେଖାକୁ OCR ସଫ୍ଟୱାର୍କୁ ପଢ଼ିବାରେ ଅସୁବିଧା ସାମ୍ନାକରିବାକୁ ପଡ଼ିଥାଏ ।
ଏହି ପ୍ରକଳ୍ପ ବିଷୟରେ ଗୁଗୁଲ୍ର ସହାୟକ ପୃଷ୍ଠାରେ ଉତ୍ପାଦିତ ଲେଖାରେ ଅକ୍ଷରର ସ୍ୱରୂପ, ଯଥା ମୋଟା ଓ ତେଢ଼ା ଅକୃତିର ସଂରକ୍ଷଣ ସମ୍ଭନ୍ଧରେ ଏହାର ଦକ୍ଷତା ବିଷୟରେ ଅତିରିକ୍ତ ବିବରଣୀ ଦିଆଯାଇଛି:
When processing your document, we attempt to preserve basic text formatting such as bold and italic text, font size and type, and line breaks. However, detecting these elements is difficult and we may not always succeed. Other text formatting and structuring elements such as bulleted and numbered lists, tables, text columns, and footnotes or endnotes are likely to get lost.
ଆପଣଙ୍କ ଫାଇଲର ଖୋଲୁଥିଲାବେଳେ ଆମେମାନେ ମୂଳଲେଖାର ସଜାଣି ଯଥା ମୋଟା ଓ ତେରଛା ଅକ୍ଷର, ଅକ୍ଷରର ଆକାର ଓ ପ୍ରକାର ଏବଂ ଧାଡ଼ି ଭଙ୍ଗା ଆଦି ସୁରକ୍ଷିତ ରଖିବାକୁ ଚେଷ୍ଟାକରିଥାଉ । ତେବେ ଏସବୁକୁ ଖୋଜିପାଇବା କଷ୍ଟକର ଏବଂ ଆମେ ସଦା ସଫଳ ହେଇନପାରୁ । ଅନ୍ୟାନ୍ୟ ଲେଖା ସଜାଣି ଓ ଉପାଦାନମାନଙ୍କ ଗଠନ ଯଥା ବିନ୍ଦୁଯୁକ୍ତ ଓ ସଂଖ୍ୟାଥିବା ତାଲିକା, ସାରଣୀ, ଲେଖା ସ୍ତମ୍ଭ ଏବଂ ପାଦଟୀକା କିମ୍ବା ଶେଷଟୀକାସବୁ ସମ୍ଭବତଃ ନଷ୍ଟ ହୋଇଯାଇଥାଏ ।
ମାଲାୟାଲାମ ଓ ତାମିଲ ଭଳି କେତେକ ଭାଷା ପାଇଁ ଓସିଆରଟି ପାଖାପାଖି ୧୦୦ ଭାଗ ସଠିକ । ଏଥିସହିତ ଏଥିରେ ଅଟୋକ୍ରପିଂ, ଛବିରୁ ଲେଖା ଅଲଗା କରିବା, ରଙ୍ଗୀନ ପଛପଟକୁ ଅଣଦେଖା କରିବା ଭଳି ସଜାଣି ଭଲ କରି ଆସିଛି ବୋଲି ଉଇକିଆଳି ରବିଶଙ୍କର ଆୟାକାନୁ ଫେସବୁକରେ ଲେଖିଛନ୍ତ:
[…] Google Tamil OCR works with 100% accuracy ! Keep testing with various samples and comment here. Performance has been the same for many other Indic languages too. […] Auto crops, discards images and colored background. Recognizes different layouts. I could find only 1 mistake in whole page. Testing latest Vikatan – https://docs.google.com/…/1OXre4…/edit.. […]
ଗୁଗୁଲ ତାମିଲ ଓସିଆର ୧୦୦% ସଠିକ କାମକରୁଛି! ଅଧିକରୁ ଅଧିକ ଭରତୀୟ ଉପମହାଦେଶୀୟ ଭାଷାରେ ପରଖି ଏଠାରେ ଲେଖିବେ ।[…] ଅଟୋ କ୍ରପ, ଛବି ଓ ରଙ୍ଗୀନ ପ୍ରଚ୍ଛଦ ଅଣଦେଖା କରୁଛି । ବିଭିନ୍ନ ସଜାଣି ବୁଝିପାରୁଛି । ମୁଁ କେବଳ ପୂରା ପୃଷ୍ଠାରେ ଭୁଲ ଦେଖିପାରୁଛି । ନିକଟର ବିକଟନ ବହିଟି ପରଖୁଛି ।
(ବଙ୍ଗଳା, ମାଲାୟାଲାମ, କନ୍ନଡ଼, ଓଡ଼ିଆ, ତାମିଲ ଓ ତେଲୁଗୁ ଭାଷାଭାଷୀ ବ୍ୟବହାରକାରୀମାନେ ନିଜ ନିଜ ଭାଷା ଓସିଆର ସଫ୍ଟୱାର୍ ପରଖି ଏହି ଲେଖା ତଳେ ମତ ଦେଇଛନ୍ତି । ଗୁରୁମୁଖୀ (ପଞ୍ଜାବୀ ଲେଖିବାରେ ବ୍ୟବହାର ହୁଏ) ଭଳି କିଛି ଲିପି ପାଇଁ ଓସିଆର ପରେ ଫଳାଫଳ ଖୁବ ଖରାପ । ପଞ୍ଜାବୀ ଉଇକିପିଡ଼ିଆରୁ ଏକ ସ୍କ୍ରିନସଟ ନେଇ ଦେଖିଲା ପରେ ଏଥିରେ ମୋଟାମୋଟି ଭୁଲ ଫଳ ମିଳୁଛି ।)
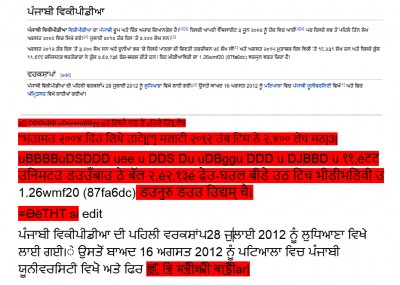
ଗୁରୁମୁଖୀ ଲିପିରେ ଗୁଗୁଲ ଓସିଆର ପରେ ଅସୁବିଧା. ପଞ୍ଜାବୀ ଉଇକିପିଡ଼ିଆର ସ୍କିନସଟ ।
ଅନେକ ପୁରୁଣା ଲେଖା ଡିଜିଟାଇଜ ହୋଇନଥିବା ଭାଷାମାନଙ୍କ ପାଇଁ ଏହା ଏକ ଲମ୍ବା ଡିଆଁ । ଏବେ ଅନେକ ପୁରୁଣା ଓ ମୂଲ୍ୟବାନ ଲେଖା ଡିଜିଟାଇଜ ହୋଇ ଇଣ୍ଟରନେଟରେ ଉଇକିପାଠାଗାର (Wikisource) ଜରିଆରେ ସାଇତାଯାଇପାରିବ ଓ ଜ୍ଞାନ ବିତରଣ ଲାଗି ଉପଲବ୍ଧ କରାଯାଇପାରିବ ।
ଗୁଗୁଲର ଓସିଆର ଆଂଶିକ ଭାବେ Tesseract ନାମକ ଏକ ଫ୍ରିୱେର ଓସିଆର ଇଞ୍ଜିନ ବ୍ୟବହାର କରେ । ୧୯୯୫ରୁ ୨୦୦୬ ଭିତରେ ଏକ ସାମୁହିକ ପ୍ରକଳ୍ପ ଭାବେ ଆରମ୍ଭ ହୋଇଥିବା (ଏହା ପରେ ଗୁଗୁଲ ଦ୍ୱାରା ନିଆଯାଇଥିଲା) Tesseract ପୃଥିବୀର ଅନ୍ୟତମ ସଠିକ ଓସିଆର ଇଞ୍ଜିନ ଭାବେ ପରିଗଣିତ । ଏହା ୬୦ଟି ଭାଷା ପାଇଁ କାମ କରେ । ଏହାର ସୋର୍ସ କୋଡ଼ https://github.com/tesseract-ocrରେ ମିଳିପାରିବ । ବିଭିନ୍ନ ଦକ୍ଷିଣ ଏସୀୟ ଭାଷାରେ ଓସିଆର ଫଳାଫଳ ପାଇଁ ଏହି ଲିଙ୍କଟି ଦେଖନ୍ତୁ ।

ନାଗରିକ ମିଡିଆ ପହଞ୍ଚିବାର ସୁବିଧା ନଥିବା ସେହି ସ୍ଥାନମାନଙ୍କରେ ଏହାକୁ ବିତରଣ କରିବାରେ ସହଯୋଗ କରୁଥିବା ଗ୍ଲୋବାଲ ଭଏସେସର ରାଇଜିଙ୍ଗ ଭଏସେସ ପ୍ରକଳ୍ପରୁ ଏହା ଏକ ଲେଖା । · ସମସ୍ତ ଲେଖା